
如何做全站采集?
很多同学加群都在问, 如何使用DotnetSpider做全站采集呢? 其实很简单, 只要你们想通爬虫的整个逻辑就能明白了。简而言之,步骤如下:
1. 使用指定URL下载HTML
2. 分析, 保存HTML数据
3. 从HTML中分析出符合规则的新的URL, 并用新URL重复 1,2,3步骤, 直到再也无法发现新的URL
逻辑是简单的, 但其中涉及到的细节不少,如多线程、URL去重、遍历深度等, 但是不用担心, 这些也正是框架应该去做的事情, 大家只需要关注业务逻辑就好。
下载代码
https://github.com/zlzforever/DotnetSpider
请下载代码后, 找到DotnetSpider.Sample里的BaseUsage.cs中的CrawlerPagesTraversal方法
public static void CrawlerPagesTraversal()
{
// Config encoding, header, cookie, proxy etc... 定义采集的 Site 对象, 设置 Header、Cookie、代理等
var site = new Site { EncodingName = "UTF-8", RemoveOutboundLinks = true };
// Set start/seed url
site.AddStartUrl("http://www.cnblogs.com/");
Spider spider = Spider.Create(site,
// crawler identity
"cnblogs_" + DateTime.Now.ToString("yyyyMMddhhmmss"),
// use memoery queue scheduler
new QueueDuplicateRemovedScheduler(),
// default page processor will save whole html, and extract urls to target urls via regex
new DefaultPageProcessor("cnblogs\\.com"))
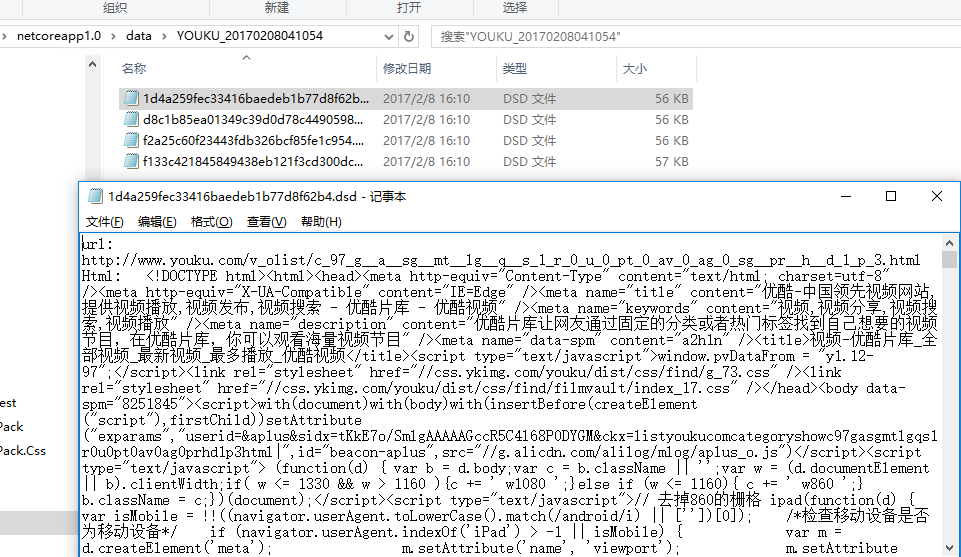
// save crawler result to file in the folder: \{running directory}\data\{crawler identity}\{guid}.dsd
.AddPipeline(new FilePipeline())
// dowload html by http client
.SetDownloader(new HttpClientDownloader())
// 4 threads 4线程
.SetThreadNum(4);
// traversal deep 遍历深度
spider.Deep = 3;
// stop crawler if it can't get url from the scheduler after 30000 ms 当爬虫连续30秒无法从调度中心取得需要采集的链接时结束.
spider.EmptySleepTime = 30000;
// start crawler 启动爬虫
spider.Run();
}
设置站点对象
Site对象是用来设置对采集对象统一使用的配置, 如Encoding, Cookie, Proxy, 页面是否压缩等等, 一般大家可以直接使用默认值就可以了, 除非发现数据采集异常, 再去尝试修正
起始链接
采集一个站点, 当然需要一个入口,这个入口一般可以是网站首页。当然如果你们要从某个类别等进入,甚至是多个入口都是可以的。调用AddStartUrl添加就可以了
site.AddStartUrl("http://www.cnblogs.com/");
创建爬虫
Spider spider = Spider.Create(site, // crawler identity
"cnblogs_" + DateTime.Now.ToString("yyyyMMddhhmmss"), // use memoery queue scheduler
new QueueDuplicateRemovedScheduler(), // default page processor will save whole html, and extract urls to target urls via regex
new DefaultPageProcessor("cnblogs\\.com")) // save crawler result to file in the folder: \{running directory}\data\{crawler identity}\{guid}.dsd
.AddPipeline(new FilePipeline()) // dowload html by http client
.SetDownloader(new HttpClientDownloader()) // 4 threads 4线程
.SetThreadNum(4);如上代码, 调用静态方法Spider.Create(有多个重载), 给的参数是站点对象、采集任务标识、调度队列(如果引用了DotnetSpider.Extension可以使用Redis做队列实现分布式采集)
DefaultPageProcessor: 构造参数是一个正则表达式, 用此正则来筛选需要采集的URL
FilePipeline: 默认实现的文件存储HTML信息, 大家可以自行实现IPipeline传入
HttpClientDownloader: 默认实现的Http下载器, 仅用于下载HTML
设置遍历深度及结束条件
// traversal deep 遍历深度
spider.Deep = 3; // stop crawler if it can't get url from the scheduler after 30000 ms 当爬虫连续30秒无法从调度中心取得需要采集的链接时结束.
spider.EmptySleepTime = 30000;
EmptySleepTime是指当爬虫多久发现不了新的URL时就结束。
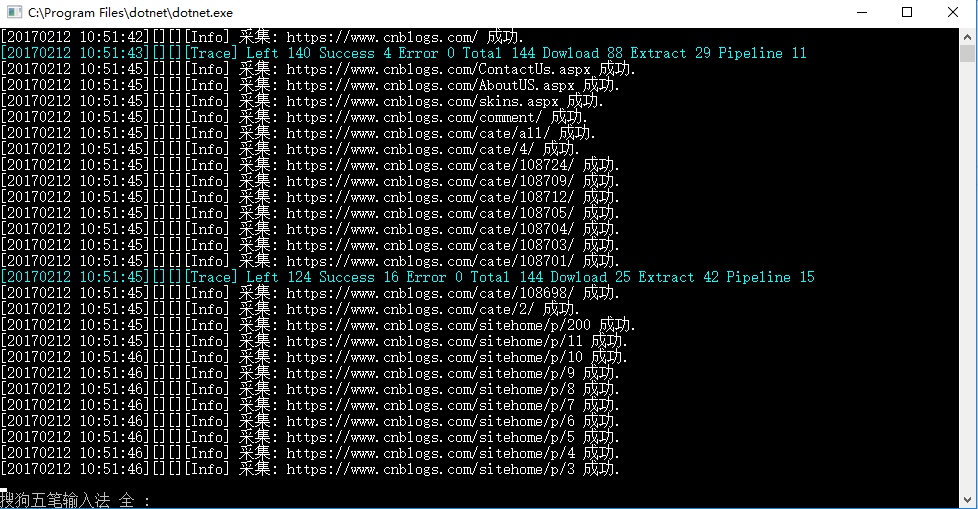
运行结果
代码地址
https://github.com/zlzforever/DotnetSpider 望各位大佬加星 :)
参与开发或有疑问
QQ群: 477731655
邮箱: zlzforever@163.com
原文地址: http://www.cnblogs.com/modestmt/p/6390564.html